── AIX1 Pro で見えた「限界の正体」と、玄人が詰めているポイント
はじめに:年末、迷っている時間そのものがコストだと感じた
2025年末、SNSや技術系コミュニティでは
「AI PCは今のうちに買え」「後で後悔する」という声が一気に増えた。
正直なところ、ああいう煽りはあまり好きではない。
だが一方で、こうも思った。
もう少し様子を見る、という判断自体が
そのまま“値上がりを待つ行為”になりつつあるのではないか。
ローカルLLMや画像生成、動画生成を本格的に評価するなら、
それなりの性能を持つ端末を一度は触っておく必要がある。
そう割り切って、年末に
AMD 370HX + 大容量メモリを積んだ “いわゆるAI向けPC” を
観測点として1台導入した。
※端末の構成や初期設定、eGPU検証などの技術的な話は
OSManiaX側にまとめているので、興味のある方はそちらを参照してほしい。
今回の目的は「移行」ではなく「比較」だった
最初に断っておくが、
今回の目的は macOS や Linux から Windows へ移行することではない。
あくまで、
- 型落ち気味の中古PCで触ってきたローカルAIと
- 「最新AI向け」と言われるPCでの体験に
- どれほどの差があるのか
それを実測ベースで確かめることが目的だった。
その上で今回は、ComfyUI/Amuse による画像・動画生成、
Ollama/LM Studio によるローカルLLM推論を一通り試した。
率直な感想:遅い、精度が安定しない、何度も繰り返すのは正直きつい
結論から言うと、率直な感想はこうだ。
画像生成AIと動画生成AIはまだまだ発展途上だと言える。
- ComfyUI は遅い(今回はGPUではなくCPU実行だったため、この点は想定済)
- AmuseはComfyUI比較では速い、しかし精度が安定しない
- 日本語プロンプトだと、確実に破綻する
モデルデータはどれも容量が大きく、
ダウンロードと差し替えだけで結構な時間を持っていかれる。
「試す」までのハードルが、思った以上に高い。
そして正直に言えば、
現時点では
クラウドの画像生成AI・動画生成AIサービスの方が
一発の完成度は圧倒的に高いんじゃないか
と感じた。
ローカル生成AIに期待していた分、このギャップに戸惑ったし、これでは正直疲れてしまう。
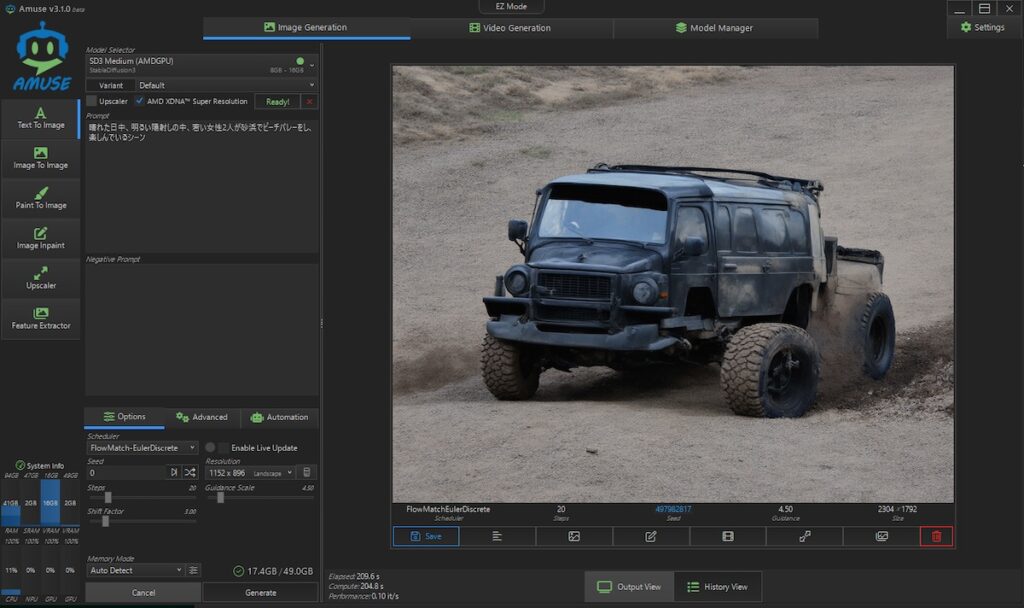
ちなみに以下はAmuseを使って実際に日本語プロンプトで破綻した事例だ
プロンプトは以下。
「晴れた日、明るい日差しの中、若い女性2人がビーチバレーを楽しんでいるシーン」なぜか、タイヤが外れかかっていそうなオフローダーが出力された。
Amuseはそもそも日本語プロンプトを前提にしていないように見える。
ちなみに多くの画像生成モデルは、英語キャプション前提だ。
そして仮に日本語指示が可能でも機械翻訳品質の学習データになり、
主語・修飾語が壊れやすいし、感情語・比喩が落ちやすい。
なので、最初から英文で渡す方がいいとなる。
というわけで、気を取り直して今度は英文に翻訳して渡してみよう。
ちなみに渡したこのプロンプトはローカルLLMのOllama(gpt-oss:20b)で翻訳生成した。
Bright sunny day on a sandy beach. Two young women, laughing and enjoying themselves, are playing beach volleyball under a clear blue sky. The sun casts warm golden light across the sparkling water and the sand, creating a lively, vibrant atmosphere.英文プロンプトで各モデルでも試してみたが、完全にプロンプト指示通りではない
今度はオフローダーではなく女性が生成された。
だが女性2人ではなく、3人になっている。
左端の女性が上半身下半身が不自然。
右端の女性はお腹が透けて背景の海になっている。
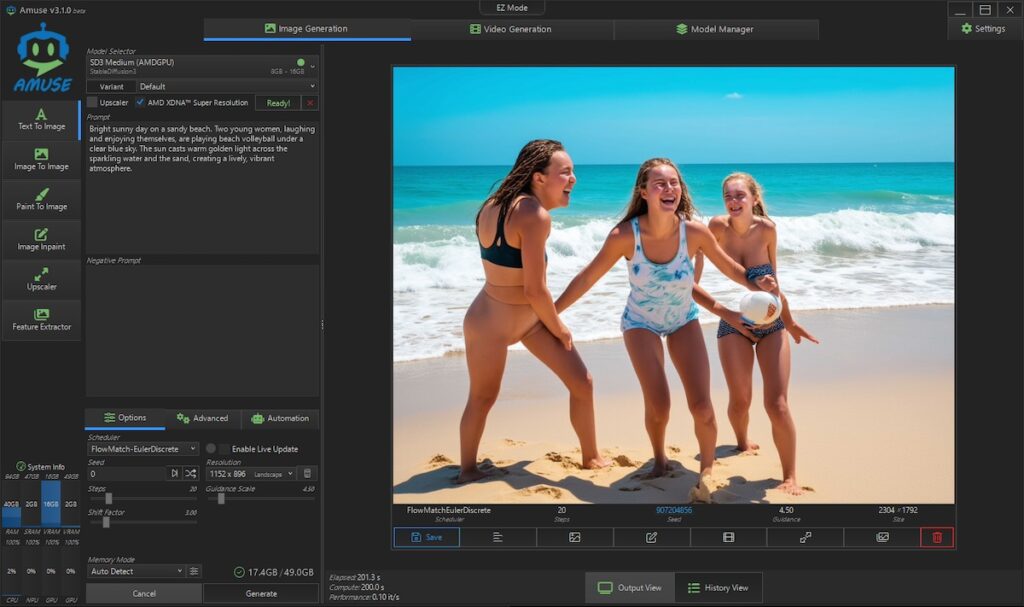
これは最初のモデル「SD3Medium(AMDGPU)」で出力したものだ。
次に同一の英文プロンプトを、設定は極力いじらず、
複数モデルでそのまま流してみた。
Fluently V4 LCM
ビーチバレーまで汲み取ってくれた、が足が3本?
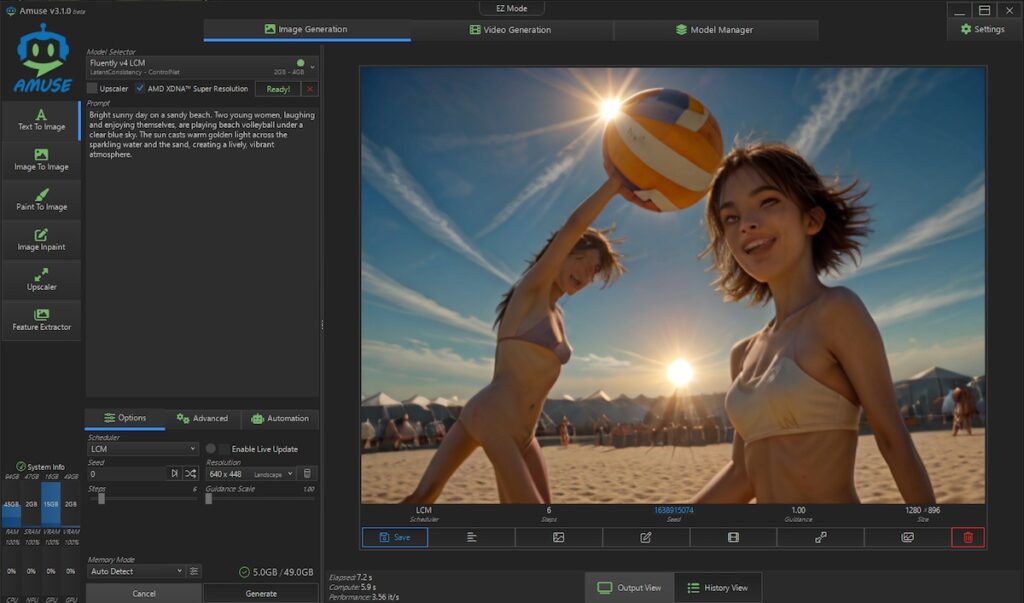
Fluently V4 LCM
ビーチバレーはない。
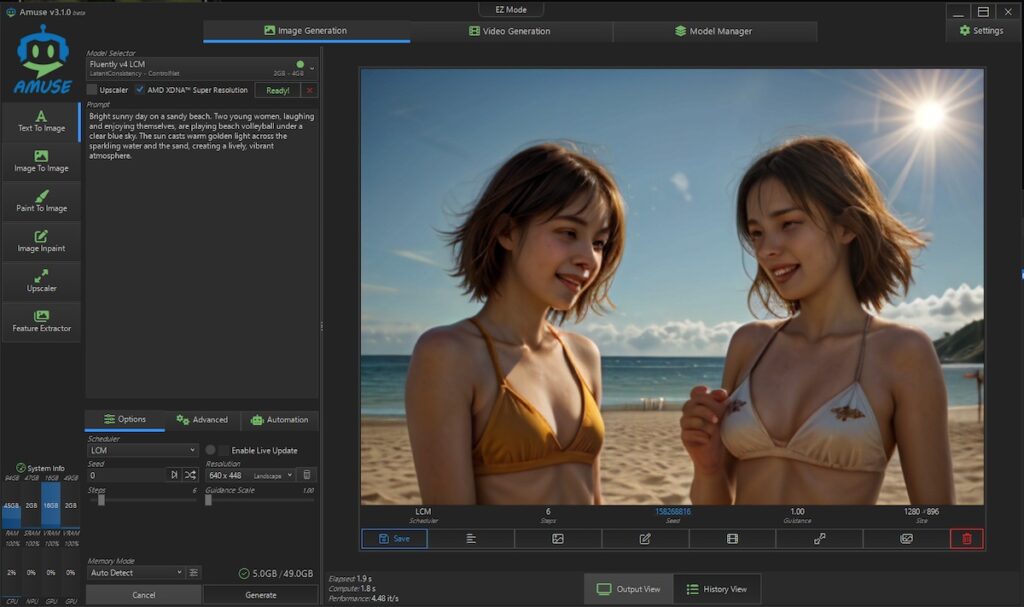
StableDiffusion
ビーチバレーはない。
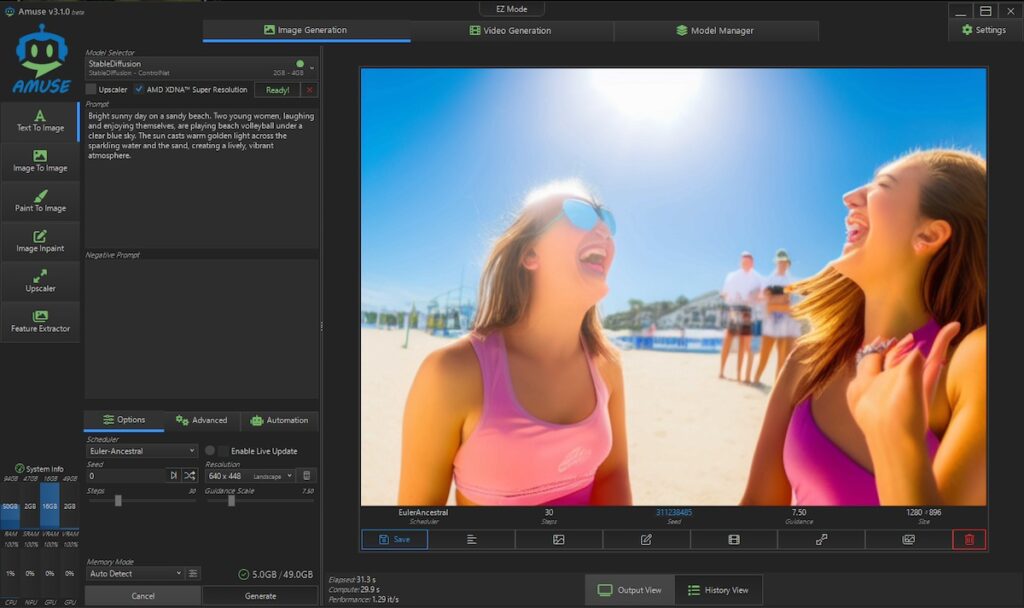
StableDiffusion
ビーチバレーはない。
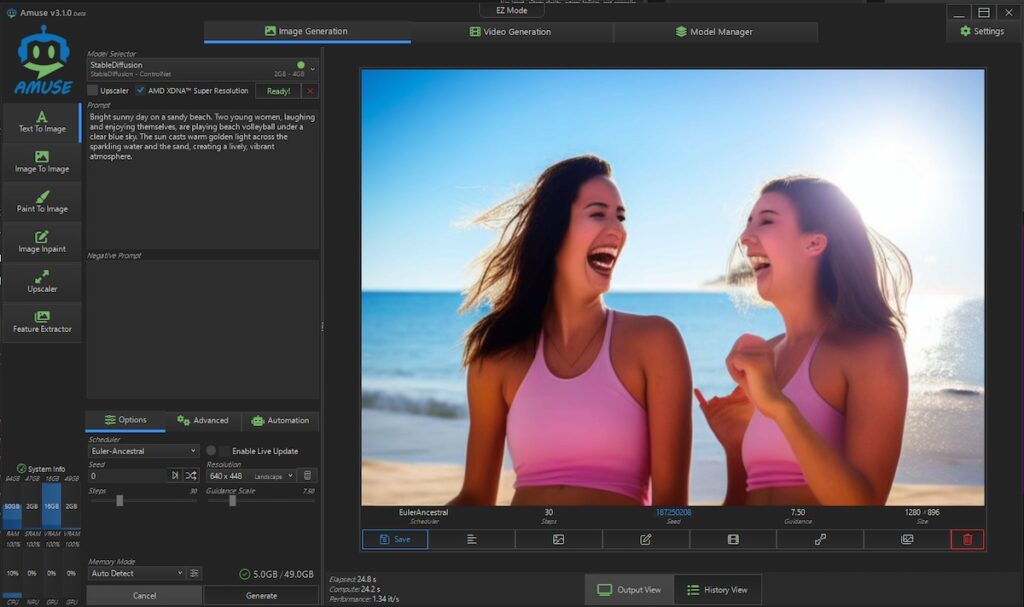
モデルはダウンロードしたが、細かい設定は変えずに、デフォルト設定での生成だとこんな具合だ。
これだとクラウド生成AIサービスのがまだマシでは、と思ってしまっても仕方がない。
では、なぜクラウドAIの方が“賢く”見えるのか
これはモデル性能の差だけではない。
結論を先に言うと、
クラウドAIは“生成前後の工程”が桁違いに多い
クラウド生成AIが裏でやっていること
- 日本語 → 英語への内部変換
- プロンプトの自動拡張
- ネガティブプロンプトの自動生成
- ControlNet相当の構図制御
- 複数候補を内部生成し、良いものだけを出力
- 失敗例はユーザーに見せない
ユーザーから見ると「1回での生成」だが、
内部では10工程以上走っているケースも珍しくない。
ローカル生成AIは「裸」で渡されている
一方、ローカル生成AIはどうか。
- モデル単体
- 補正なし
- 文脈補完なし
- 失敗もそのまま出力
つまり、
クラウドAIは完成した工場ライン
ローカルAIは素材と工具
同じ土俵で比べるのが、そもそも無理がある。
玄人向け:それでもローカルで精度を上げる方法
ここまでは、とりあえず、デフォルトで用意されたものをやってみたという段階だ。
ここからが重要だ。ある程度チューニングをすることで改善が見込める部分があると言える。
「だからローカルAIはダメ」で終わらせたくはない。
まずは以下4点だ。
① 日本語 → 英語プロンプト変換を挟む
ローカルLLM(LM Studio / Ollama)を使い、
- 日本語の意図を
- 英語の“生成向け命令文”に変換する
これだけで、出力の安定性は一段上がる。
② プロンプトは短く、固定化する
- 曖昧な形容詞を減らす
- 毎回違う詩を書かない
- Seed を固定する
ローカル生成は設計図を書く感覚が重要だ。
③ ネガティブプロンプトを厚くする
クラウドAIが裏でやっていることを、
ローカルでは手で書く必要がある。
- 手・指・顔の崩れ
- ノイズ
- 文字化け
- 解像感低下
④ ControlNet 前提で考える
一発芸を狙わない。
- 構図
- ポーズ
- 世界観
を分離して組み立てる。
ローカル生成AIの正しい立ち位置
ローカル生成AIは、
- 一発で映える魔法ではない
- だが、制御・自動化・コスト固定では強い
手っ取り早く生成AIの動画で作品を作りたいという人はクラウド生成AIを使うべきだろう。
そういう意味では「課金してでも作品を作りたい人向け」だ。
ローカル生成AIは自分で何か仕組み化したい人向けの道具になると言える、試行錯誤しながら何かしら自分用のツールや、アイディアが当たれば多くの人に利用可能なWEB生成AIサービスを作りたい。というような人向けなんじゃないかなと思う。基盤となる「道具を作りたい人向け」だと言える。
この住み分けを理解すると、期待外れだった体験も、違う意味を持ち始める。
おわりに:失望は、理解の入口だ
今回、最新と言われるPCでローカル生成AIを触ってみて、
まだ全てを理解しているわけではないため、
各種設定などを理解した上で、最適な環境を構築していきたい。
まだ今はまずは最初はこんなもんかという感情である。
ここからどう改良されていくのか、伸び代はまだあるので、それに期待しているところだ。
ローカル生成AIは、まだ“誰でも一発で当てられる魔法”ではない。
だが、使いどころと期待値を正しく置けば、確実に武器になる。
常に勉強し続けることでしか前に進めないのだと改めて感じた2026年初頭である。