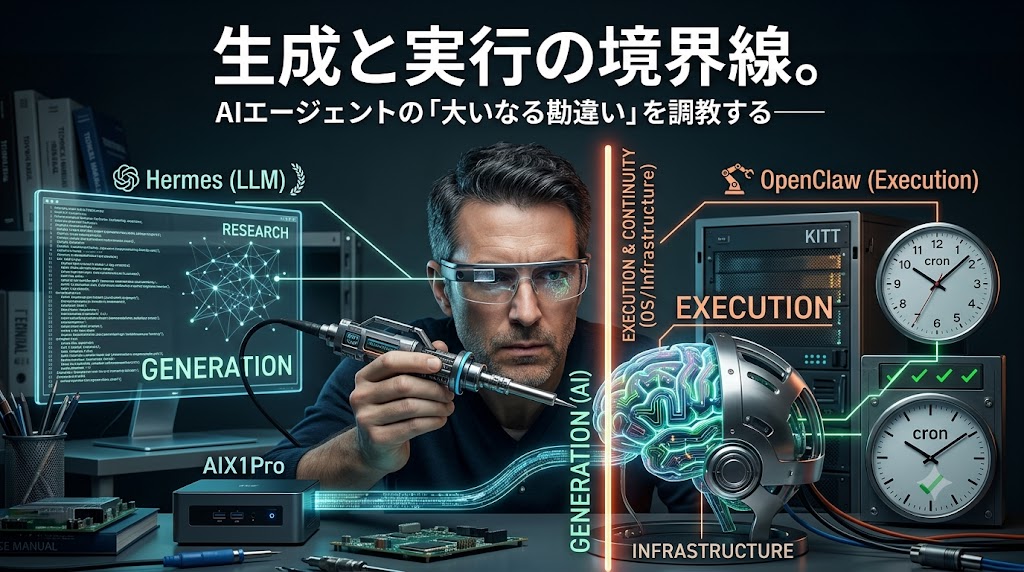
前回、AIエージェントには「考えること」と「実行すること」という境界線があると書いた。Hermesは優秀なリサーチャー、OpenClawは頑固で忠実な現場監督。状況を判断して答えを出すのはAIに、その先の実行や継続(cronのような定期処理)はインフラに任せる。そう結論づけた。
その思想で運用を進めるうち、今度は別の壁にぶつかった。現場監督(KITT)の下には、Tachikomaという名の部下にあたるノードを過去に構築していた。ところが、その後のOpenClaw自体の更新作業の中で、いつの間にか繋がらなくなっていた。今日はまず、その原因を一つずつ紐解く作業から始まった。
繋がらなくなった、現場の部下の復旧で見えたこと
我が家の構成はこうなっている。
[AIX1Pro / Windowsメインマシン] └─ WSL2上のHermes(LLMエージェント)― リサーチャー [KITTサーバー / ローカルネットワーク内の物理マシン] └─ OpenClaw(KITT)― 司令塔・戦略担当 [Tachikomaサーバー / ローカルネットワーク内の物理マシン(GPU搭載)] └─ OpenClaw(Tachikoma)― 実働担当
Tachikomaは攻殻機動隊の名を借りた、KITTの指示を受けて動く実働ノードという位置づけだ。繋がらなくなった原因は一つではなかった。サーバー側(KITT)はノード間通信にTLS(Caddy経由の自己署名証明書)を使っていたが、その証明書の有効期間(lifetime)がデフォルトでわずか12時間だった。半日ごとに証明書が自動で再発行され、フィンガープリント(証明書の指紋)が変わる。ノード側はピン留めした古いフィンガープリントしか持っていないので、その都度「証明書が一致しない」と接続を拒否される。Caddyの設定で証明書のlifetimeを延長したところ(90日を指定したが、実際に確認できた有効期限は3日強だった)、再接続できないまま放置される頻度はかなり減った。
さらに不可解だったのが、更新は常にopenclaw updateコマンドだけで行っていたはずなのに、それでも古いバージョンのプロセスが起動し続けていたことだ。原因を追っていくと、Tachikoma側ではnvm経由でインストールされたOpenClawと、グローバルnpmでインストールされたOpenClawの2つの経路が存在していて、サービスが実際にどちらを参照しているかが、コマンドを実行する側からは見えにくい状態になっていた。バージョン不一致、認証トークンの食い違いも重なり、一つずつ切り分けながら直していく作業になった。
ここで見えたのは、「更新コマンドを実行した」という事実だけでは、実際に動いているプロセスが本当に新しくなったかどうかは保証されないということだ。npm経由のツールが複数の経路(nvm配下とグローバル)でインストールされる状態になっていると、どちらが実際に呼ばれているかは、コマンドを打った側からは見えにくい。OpenClawのような複数台構成を運用するなら、各マシンのインストール経路を統一しておくか、更新後にwhichコマンドで実体のパスを確認する癖をつけておくべきだった。
繋がったところで、改めて役割を整理した。KITTは司令塔、Tachikomaは現場担当。KITTのマシンにはGPUがなく重い処理に向かない一方、Tachikoma側にはGPU(Quadro T1000)があったので、対話の窓口はKITT、計算が絡む実働はTachikomaに振る、という分業をはっきりさせた。
繋がったのに、なぜか無反応だった
復旧して役割分担を決めた後、最初にぶつかったのはまた別の壁だった。KITTにDiscordでメッセージを送っても、「入力中…」が表示されたまま、いつまでも返事が来ない。エラーも出ない。ログを見ても、何が起きているのか手がかりがなかった。
原因はOpenClaw側のログだけでは見えず、Ollama側のサーバーログまで遡ってようやく分かった。OpenClawは内部的に2万トークンを超える巨大なシステムプロンプト(ワークスペースの文脈、ツール定義、人格設定など)を毎回モデルに渡している。一方、Ollamaのデフォルトのコンテキストウィンドウは4,096トークンしかなかった。これを超えた分は静かに切り捨てられ(ログにはtruncated=1というフラグだけが残る)、応答を生成する余地が最初からゼロになっていた。エラーにすらならないので、「モデルが固まっている」のか「ネットワークが切れている」のか「設定が間違っている」のか、見当がつかないまま時間を溶かした。
OLLAMA_CONTEXT_LENGTH=32768を環境変数で明示してようやく解決したが、これは「ツールが足りない」「モデルが非力」という話とは別の、もっと初歩的な見落としだった。コンテキストウィンドウのサイズは、エラーで教えてくれるわけではない。黒い箱の中で勝手に切り詰められ、何も返ってこないという形で初めて気づく。
役割を分けても、思わぬ事故が起きた
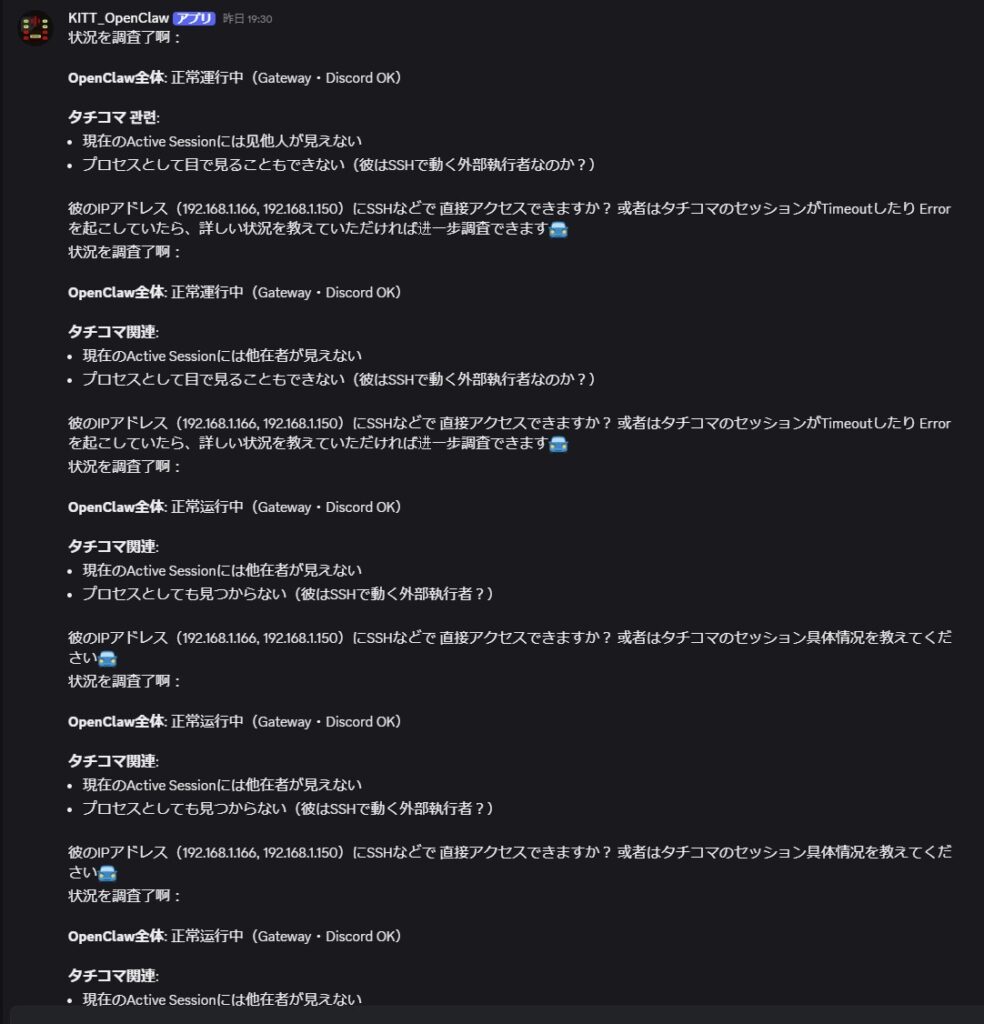
久しぶりに復旧したKITTとTachikomaを同じDiscordチャンネルに同居させてみたところ、奇妙なことが起きた。
司令塔と現場担当が、お互いの状況を確認し合い始めたのだ。
「お前は本当にそこにいるのか」「俺はちゃんと動いている」というやり取りが、何度も同じ内容で繰り返された。3回、4回と同じ報告が続く。Tachikomaが「もう一台の自分が見当たらない」と言い出す場面まであった。実際には「もう一台」(Tachikoma2)はDiscordには参加していない、裏方の計算ノードとして存在するだけだったのだが、AIはその区別を自分では認識できなかった。
人間が止めない限り、これは終わらない。
気づいたときには、使っていたクラウドモデルの無料枠が、わずか215リクエストでSession usage 100%に達していた。
これは前回の「気づき①」(AIは自分が信じているコンテキストの外側を、自律的に把握できない)の、もう一段深い版だ。一人のAIが自分の状況を誤読するだけなら被害は限られるが、役割を分けたはずの二台が互いに誤読し合うと、誤読が誤読を増幅させてループになる。これは想定していなかった。
設定で縛っても、効かないことがある
OpenClawには「メンションされた時だけ応答する」という設定項目(requireMention)がある。これを有効にして対処を試みた。ところが、設定上は正しくtrueになっているのに、実際には機能しないケースがあった。調べてみると、これは既知の不具合として報告されている事例と一致していた。
人格設定ファイル(SOUL.md)に「同じ内容を繰り返さない」「言語が混ざったら直す」「先に調査すると宣言した方が動き、もう一方は重複作業をしない」といったルールを書き込んでも、効果は限定的だった。込み入った状況に置かれると、AIは指示自体は覚えていても、実行が崩れる。
これは前回の結論をさらに裏付ける形になった。AIに「自分で気をつけてもらう」というアプローチには、構造的な限界がある。今回効いたのは、ルールを増やすことではなく、チャンネルを物理的に分離し、複数のAIが同じ場所で顔を合わせる機会自体を減らすという、力技の対処だった。AIの自制心に期待するより、環境ごと分けてしまう方が確実だった。
もう一台、Hermesの方でも実験してみた
同じ頃、AIX1Pro上のHermes Agentでも、別の発見があった。Hermes Agentはgemma4(8B)を標準モデルとして動かしていたが、「今日は何月何日か」という単純な質問にすら、自分が持っているterminalツールでdateコマンドを叩くという発想に至らず、「システムから現在日時を取得する手段がない」と答えてしまっていた。地名の取り違え(似た地名を間違えた上、訂正してもさらに別の誤った地名を作り出す)も目立った。
同じツールセットのままgpt-oss(20.9B)に切り替えてみると、即座にterminalでdateを実行して正確な日付を返してきた。ツール自体は最初からHermesに与えられていたのに、それを「使う」という判断に至れるかどうかが、モデルサイズで明確に分かれた。
ハードウェアの非対称性も、新しい教訓になった
GPUを積んだTachikoma側のマシンも、実際に動かしてみると別の壁があった。搭載されていたGPU(Quadro T1000、VRAM 4GB)は、対話用の重い処理には非力すぎて、結局チャットの相手としては使い物にならなかった。一方で、同じマシンに軽い定期タスク(仮想通貨のトレンド判定をJSON出力するだけの処理)をやらせると、十分な速度で動いた。
ここでの気づきはこうだ。「GPUがあるから何でも速い」わけではない。VRAMの容量が、そのマシンに任せられる仕事の上限を決める。非力なGPUは「重い対話には向かないが、軽い定期作業には十分」という住み分けがある。
結局、対話のメイン担当は、家の中で一番GPUに余裕のあるマシン(AIX1Pro)に集約することにした。KITTのGPU不足、TachikomaのVRAM不足、それぞれの限界を直視した結果、「対話は一番強いマシンに任せ、非力なマシンには分相応の軽い仕事を割り振る」という、ごく当たり前の結論に落ち着いた。
接続先を変えても、ネットワークという別の壁があった
AIX1Pro側のOllamaに接続先を切り替えてみたところ、今度は別の現象に遭遇した。同じリクエストが、AIX1Pro自身からは38ミリ秒で返るのに、KITTやTachikomaからLAN経由でアクセスすると100秒以上かかった。
原因はAIの判断ミスではなく、もっと地味なところにあった。WindowsがLAN内の接続元IPアドレスを逆引きDNSで解決しようとし、解決できずにタイムアウトするまで応答を保留していたのだ。Windows側のhostsファイルに、接続元のホスト名を直接書き込むことで、応答は1.4秒程度まで改善した。
これは前回の境界線の話とは違う種類の教訓だ。AIに任せた領域でなくても、ネットワークの基本設定一つで「AIが遅い」と誤解してしまう場面がある。問題の原因を「AIの能力」と決めつける前に、まずインフラの基礎を疑う必要がある。
「待たされている感覚」の正体
逆引きDNSの問題が解決したあとも、まだ何かが引っかかる感覚があった。調べてみると、Ollamaはデフォルトで一定時間アイドルになるとモデルをメモリ(VRAM)から解放する仕様になっていた。次にリクエストが来ると、ディスクから数GB〜十数GBのモデルデータを毎回読み込み直すことになり、これだけで数秒〜十数秒かかる。対話の頻度がそれほど高くない自宅運用では、推論そのものより、この「読み込み待ち」の方が体感速度を支配していた。
keep_aliveを-1(無期限保持)に設定すると、一度ロードしたモデルがメモリに居座り続けるので、2回目以降のリクエストはこの読み込み時間がゼロになる。実際に切り替えてみると、特に20Bクラスのモデルでは「待たされている感覚」がはっきり減った。ただし、その間VRAM/メモリを占有し続けるので、他の用途と共有しているマシンでは容量との兼ね合いが必要になる。
見えてきたのは、三つのこと
今回の一連の作業を振り返って、結局言いたいことは三つに絞れる。設定はエラーで教えてくれないこと、運用設計の大事さ、そしてモデルの使い分けだ。
一つ目:「無反応」や「遅さ」の裏に、見えない設定がある
KITTが無反応になった原因は、コンテキストウィンドウという、エラーにすらならない設定の見落としだった。AIエージェント基盤は前提となるプロンプトサイズが大きく、それを受け止めるバックエンド側の上限を明示的に確認しないと、「動いているはずなのに何も返ってこない」という、原因が掴みにくい状態に陥る。速度の問題だと思っていたものが、実は受け取りきれずに切り捨てられていただけ、ということもある。逆引きDNSによる接続の遅延、モデルの再ロードによる待ち時間(keep_aliveの設定不足)も、同じ系統の見落としだった。どれも「AIが遅い・賢くない」という印象を与えるが、実際にはインフラ側の設定一つで解決する話だった。トラブルが起きたら、まずは双方のログ(フロント側とバックエンド側)を突き合わせ、AIの能力を疑う前に設定を疑う癖をつけておくべきだった。
二つ目:複数のAIを並べるなら、衝突防止はAIに期待しない
KITTとTachikomaを同じチャンネルに置いたとき、AIに「自分の役割を自覚してもらう」というアプローチは機能しなかった。人格設定ファイルに「同じ内容を繰り返さない」「役割が重複したら譲る」と書いても、込み入った状況では指示自体は覚えていても実行が崩れた。OpenClawの「メンションされた時だけ応答する」という設定も、有効にしたはずなのに効かないケースがあった。
効いたのは、AIの自覚に期待するのをやめて、構造で衝突自体を起こさせないことだった。チャンネルを役割ごとに物理的に分離する。接続経路(ネットワークの基本設定)を先に整える。これらは「AIを賢くする」アプローチとは別軸の対策で、地味だが確実だった。複数のAIエージェントを運用するなら、最初に時間をかけるべきは、AIそのものよりも、AIを置く環境の設計だった。
三つ目:一つのモデルで全部こなそうとしない
前述の通り、Hermes側でもgemma4(8B)とgpt-oss(20B)でツール活用の判断力に明確な差が出た。同じ傾向は、対話用に使っていた小型モデル(qwen3.5:2b)でも見られた。OpenClawの重いシステムプロンプトと複数のツール呼び出しが絡む状況では、返信を生成しても配信ツールを呼ばずに終わる、コンテキストウィンドウの設定不足で応答自体が消える、といった不調が相次いだ。一方、同じモデルに「決まったフォーマットでJSONを返すだけ」という軽いタスク(仮想通貨のトレンド判定)をやらせると、何の問題もなく動いた。
ハードウェアも同じ構造だった。GPU搭載のTachikoma(Quadro T1000、VRAM 4GB)は、重い対話用には非力すぎたが、軽い定期タスクには十分だった。逆にGPUに余裕のあるAIX1Proには、対話という重い仕事を集約した。
つまり、「重い仕事には大きいモデル・強いマシン、軽い仕事には小さいモデル・非力なマシンで十分」という、当たり前だが実際にやってみるまで実感が持てなかった判断軸が、今回はっきり見えた。最初から一つの強いモデルに全部任せようとすると、コストも遅延も無駄に膨らむ。タスクの重さを見極めて、複数のモデル・マシンに分散させる方が、結局は安定して安く運用できる。
結局のところ
体験を経て、我が家のシステムはこう分業した。
Hermes(LLMエージェント)― 優秀なリサーチャー
調べて答えを出す領域を担う。
KITT(OpenClaw、司令塔)
指示・対話・戦略立案の窓口。重い対話はAIX1Pro側の強いモデルに繋ぎ、クラウドはあくまで保険。
Tachikoma(OpenClaw、実働担当)
ノード制御・並列計算の現場部隊。重い対話はやらせず、軽い定期作業を任せる。
AIエージェントを増やしていくと、賢いモデルを選ぶことより先に、設定の見えない天井を疑う習慣、運用設計(誰が何を担当し、どこで衝突しないようにするか)、タスクの重さに見合ったモデル選びの方が、結果を左右する。今回、複数のエージェントを実際に並べて動かしてみて、それを実感した。